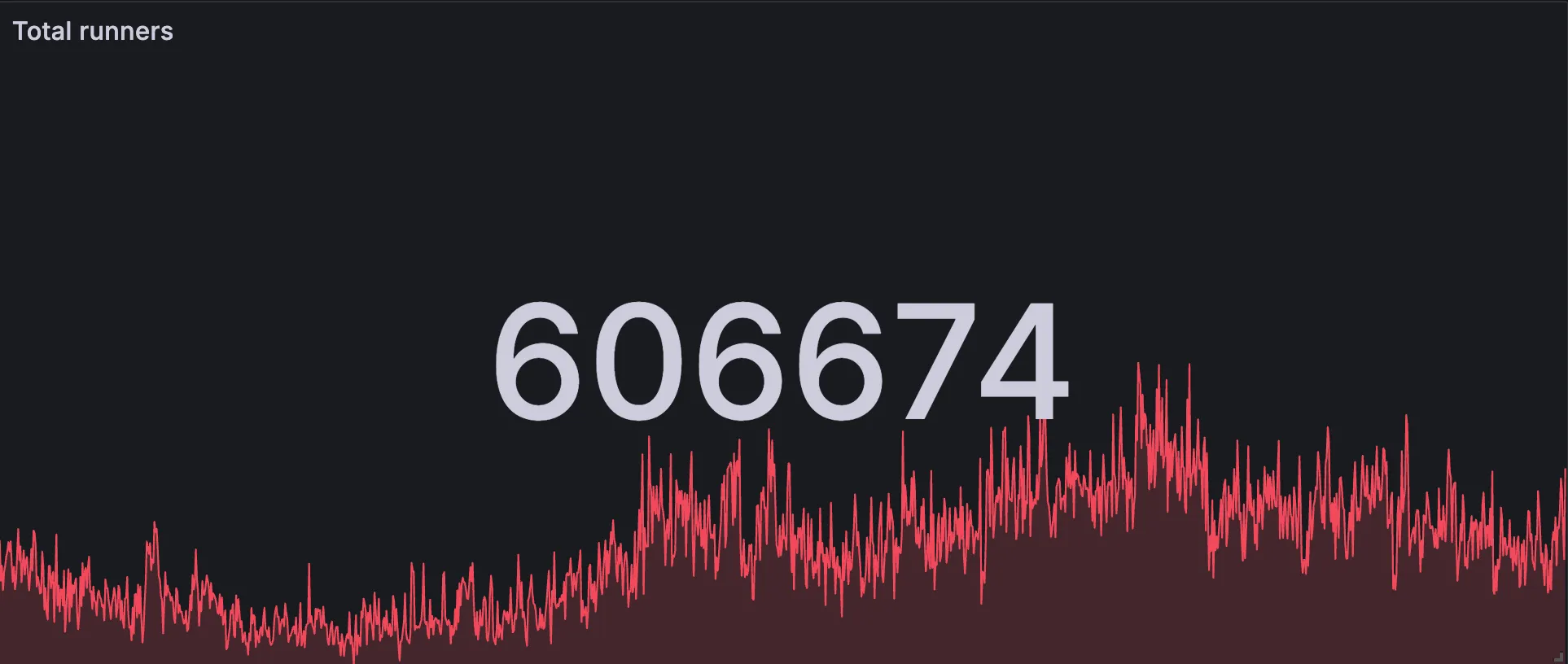
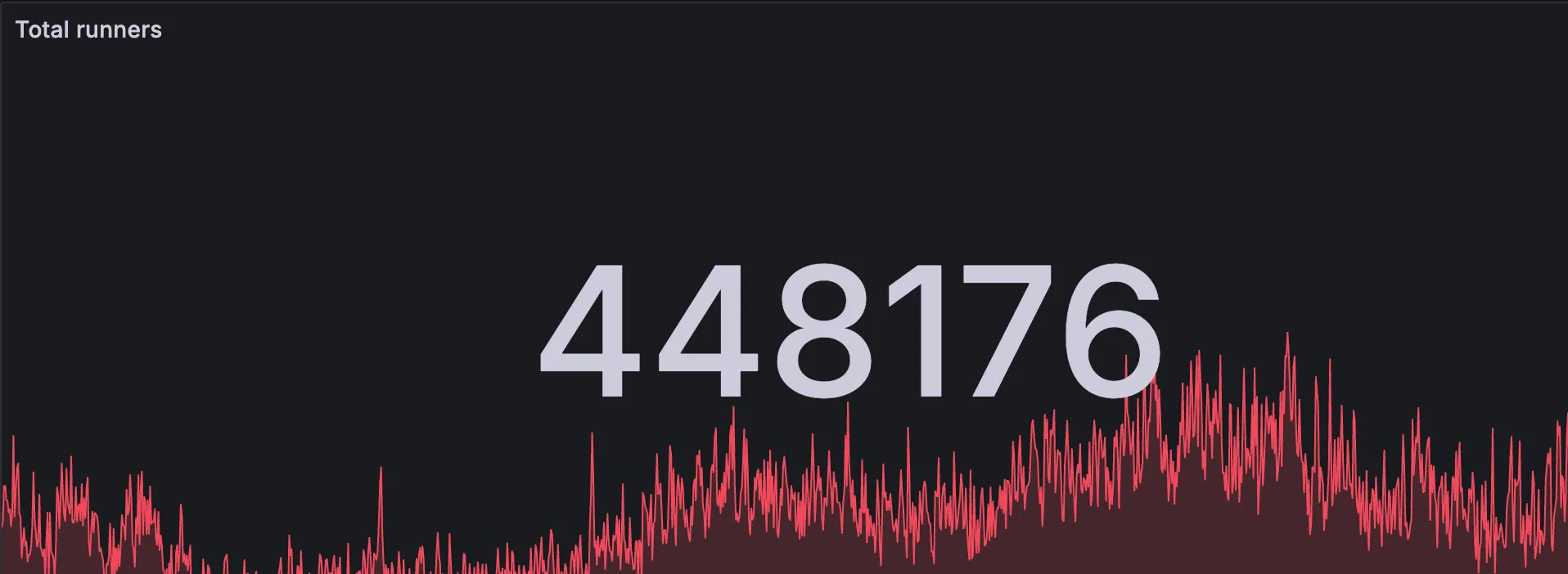
Here’s a question that separates senior engineers from the rest: Should your GitHub Actions runners live forever or die after each job?
If you answered “live forever,” you’re probably still debugging why your CI randomly fails on Tuesdays.
Long-lived runners feel intuitive. Spin up a VM, register it with GitHub, let it churn through jobs. No startup overhead, no provisioning delays. It’s the CI equivalent of keeping your laptop running 24/7 because “booting takes too long.”
But here’s what actually happens:
- Week 1: “Our runners are blazing fast!”
- Week 3: “Why do tests pass locally but fail in CI?”
- Week 6: “Let’s restart all runners and see if that fixes it.”
- Week 12: “We need a dedicated person to babysit our CI infrastructure.”
Sound familiar?
Your runner accumulates garbage like a browser with 847 open tabs. Docker layers, npm caches, environment variables, temp files—each job leaves traces. Eventually, Job #847 fails because Job #23 left some Node modules lying around.
Memory fragments. Disk fills up. CPU gets pinned by zombie processes. What started as a c5.large performing like a c5.large slowly becomes a c5.large performing like a t2.micro having an existential crisis.
That environment variable someone set for debugging last Tuesday? Still exported. That SSH key generated for a one-off deployment? Still in ~/.ssh. Your “clean” runner is basically a museum of security vulnerabilities.
Bugs that only appear after the runner has processed exactly 47 jobs involving TypeScript compilation. Good luck reproducing that locally.
Ephemeral runners are the Marie Kondo approach to CI: if it doesn’t spark joy (i.e., it’s not your current job), thank it and throw it away.
Every job gets:
- A pristine environment identical to your base image
- Zero state from previous executions
- Consistent resource allocation
- Perfect isolation from other workloads
The math is simple:
- Long-lived: Pay for 24/7 × N runners × mysterious overhead
- Ephemeral: Pay for actual job runtime × spot pricing discount
The classic objection: “Ephemeral runners are slow because of boot time!”
This is 2025 thinking with 2015 assumptions. Modern ephemeral runners boot in under 30 seconds. Your Docker build probably takes longer to download base images.
Plus, what’s worse: 30 seconds of predictable startup time, or 3 hours debugging why your integration tests only fail on runner-07 when Mars is in retrograde?
We’ve processed millions of jobs with this approach. Here’s how we make it work:
- 30-second boot times with optimized AMIs and provisioned network throughput
- Spot instance compatibility for 75% cost savings
- One runner per job ensures perfect isolation
- Zero operational overhead because there’s no state to manage
When your job finishes, the runner gets terminated. No cleanup scripts, no monitoring dashboards, no 3 AM alerts about runner-14 being “unhealthy.”
Long-lived runners are like global variables in code—they seem convenient until they’re not, and by then you’re too deep to refactor easily.
Ephemeral runners are like pure functions: predictable inputs, predictable outputs, no side effects. The kind of architecture that lets you sleep soundly knowing your CI isn’t a ticking time bomb.
Your security team gets perfect isolation. Your finance team gets usage-based costs. Your developers get consistent, reproducible builds. Everyone wins except the person who has to maintain the old system (which is no longer you).
If you’re still running long-lived CI infrastructure in 2025, you’re optimizing for the wrong metrics. You’re choosing theoretical performance over actual reliability, imaginary cost savings over real operational simplicity.
Smart money is on ephemeral. Smart developers choose tools that scale without accumulating technical debt.
Make the smart choice. Try RunsOn today.